公正與機器學習-簡介
來源:FAIRNESS AND MACHINE LEARNING
原文作者:Solon Barocas and Moritz Hardt and Arvind Narayanan
我们的成功、幸福和福祉从来不是完全由我们自己创造的。其他人的决定会深刻地影响我们的生活进程:是否录取我们到某所学校,为我们提供工作,或为我们提供抵押贷款。因此,任意的、不一致的或错误的决策引起了严重的关注,因为它有可能限制我们实现自己设定的目标和获得我们有资格获得的机会的能力。
那么,我们如何确保这些决定是以正确的方式和理由作出的?虽然固定的规则有很多价值,但在一贯的应用中,*好的决定会考虑到现有的证据。我们希望录取、就业和贷款的决定能建立在与感兴趣的结果相关的因素上。
识别与决策相关的细节可能是非正式的,而且不需要考虑太多:雇主可能会观察到学习数学的人似乎在金融行业表现特别好。但他们可以通过研究一个人的专业与工作成功的相关程度来检验这些观察与历史证据。这是统计学的传统工作–它有望通过量化在我们的判断中赋予某些细节多少权重,为决策提供一个更可靠的基础。
几十年的研究已经将统计模型的准确性与人类的判断,甚至是具有多年经验的专家进行了比较,并发现在许多情况下,数据驱动的决策战胜了那些基于直觉或专业知识的决策。4899 (1989): 1668-74. 这些结果受到了欢迎,因为它可以确保影响我们生活机会的高风险决策既准确又公平。
机器学习有望为决策带来更大的纪律性,因为鉴于历史证据中关系的复杂性或微妙性,它提供了发现人类可能忽略的与决策相关的因素。机器学习不是从某些因素和感兴趣的结果之间的关系的直觉出发,而是让我们把相关性问题推到数据本身:在我们观察到的所有因素中,哪些因素与结果有统计学上的关系。
揭开历史证据中的模式,甚至比这似乎暗示的更强大。最近在计算机视觉方面的突破–特别是物体识别–揭示了模式发现可以达到的程度。在这个领域,机器学习帮助克服了人类认知的一个奇怪的事实:虽然我们可能能够毫不费力地识别场景中的物体,但我们无法指定我们赖以做出这些判断的一整套规则。我们无法手工编码一个程序,详尽地列举所有相关因素,使我们能够从每个可能的角度或在所有潜在的视觉配置中识别物体。机器学习旨在解决这个问题,它放弃了通过明确的指令来教计算机的尝试,而采用了通过实例学习的过程。通过让计算机接触许多包含预先识别的物体的图像实例,我们希望计算机能够学会可靠地将不同的物体彼此区分开来以及从它们出现的环境中区分出来的模式。
这可以说是一个了不起的成就,不仅因为计算机现在可以执行复杂的任务,而且还因为决定图像中出现什么的规则似乎是从数据本身产生的。
但是,从实例中学习存在着严重的风险。学习不是一个简单地将例子存入记忆的过程。相反,它涉及到从例子中归纳:磨练那些一般猫的特点的细节,而不仅仅是碰巧出现在例子中的特定猫。这就是归纳的过程:从具体的例子中得出一般的规则–这些规则有效地说明了过去的情况,但也适用于未来的、尚未看到的情况。希望我们能够弄清楚未来的案例如何可能与过去的案例相似,即使它们并不完全相同。
这意味着,要想从历史案例中可靠地归纳出未来的案例,需要我们为计算机提供*好的例子:足够多的例子来发现微妙的模式;足够多的例子来展示物体可能采取的许多不同类型的外观;足够多的注释充分的例子来为机器学习提供可靠的基础真理;等等。因此,基于证据的决策只有在它所依据的证据上才是可靠的,而高质量的例子对机器学习来说是至关重要的。机器学习是 “基于证据 “的,但这并不能确保它能产生准确、可靠或有意义的结果。
在使用机器学习为人类行为和特征建模时,这一点尤其真实。我们的相关结果的历史例子几乎总是反映出对某些社会群体的历史偏见、普遍的文化成见和现有的人口不平等。而在这些数据中寻找模式,往往意味着复制这些相同的动态。
我们写这本书时,机器学习开始在特别重要的决策中发挥作用。在刑事司法系统中,被告被分配到统计分数,旨在预测未来犯罪的风险,这些分数为保释、判刑和假释的决定提供信息。在商业领域,公司使用机器学习来分析和过滤求职者的简历。当然,统计方法也是贷款、信贷和保险承保的基础。
同时,机器学习为日常应用提供动力,这些应用相比之下可能显得无足轻重,但却共同对塑造我们的文化产生了强大的影响:搜索引擎、新闻推荐器和广告定位算法影响了我们的信息饮食和世界观;聊天机器人和社交推荐引擎调解了我们与世界的互动关系。
本书试图调查这些和其他许多机器学习应用中的风险,并对一系列新兴的拟议解决方案进行批判性的审查。它将展示即使是用心良苦的机器学习应用也可能产生令人反感的结果。它还将介绍描述这些问题的正式方法,并评估解决这些问题的各种计算方法。
人口结构的差异
亚马逊使用一个数据驱动的系统来决定在哪些街区提供免费的当日送货服务。我们不知道亚马逊的系统如何运作的细节,尤其是我们不知道它在多大程度上使用了机器学习。媒体报道的许多其他系统也是如此。尽管如此,当一个用于手头任务的机器学习系统会合理地表现出同样的行为时,我们将把这些作为激励的例子。2016年的一项研究发现,这些社区的人口构成存在明显的差异:在许多美国城市,白人居民居住在合格社区之一的可能性是黑人居民的两倍以上。它应该吗?” ( https://www.bloomberg.com/graphics/2016-amazon-same-day/ , 2016)。
在第二章中,我们将看到如何使我们对人口差异的直觉在数学上变得精确,而且我们将看到有许多可能的方法来衡量这些不平等现象。这种差距在机器学习应用中的普遍性是本书关注的一个关键问题。
当我们观察到差异时,这并不意味着系统的设计者有意让这种不平等现象出现。从意图之外看,重要的是要了解什么时候观察到的不平等可以被认为是歧视。反过来,要问的两个关键问题是,这些差异是否有理由,以及它们是否有害。这些问题很少有简单的答案,但哲学和社会学中关于歧视的大量文献可以帮助我们推理。
为了理解为什么亚马逊系统中的种族差异可能是有害的,我们必须牢记美国的种族偏见的历史,它与地理隔离和差异的关系,以及这些不平等随着时间的推移而持续存在。亚马逊辩称,其系统是合理的,因为它是基于效率和成本考虑而设计的,种族不是一个明确的因素。尽管如此,它的效果是以种族差异的比率向消费者提供不同的机会。令人担忧的是,这可能会促使不平等的长期循环持续下去。相反,如果该系统被发现偏向于以奇数结尾的邮政编码,它就不会引发类似的抗议。
术语偏见经常被用来指算法系统中因社会原因而令人反感的人口统计差异。我们将在本书中避免使用这个意义上的偏见,因为它对不同的人意味着不同的东西。在统计学和机器学习中,偏见这个词有一个更传统的用法。假设亚马逊对交货日期/时间的估计一直都过早地出现了几个小时。这将是一个统计偏差的案例。如果一个统计估计器的预期值或平均值与它要估计的真实值不同,那么它就被说成是有偏见的。统计偏差是统计学中的一个基本概念,并且有一套丰富的既定技术来分析和避免它。
还有许多其他的衡量标准来量化预测者或估计者的理想统计属性,如精确度、召回率和校准。这些也同样得到了很好的理解;它们都不需要任何关于社会群体的知识,而且测量起来也相对简单明了。统计学和机器学习中对人口标准的关注是一个相对较新的方向。这反映了我们对机器学习系统的概念以及构建这些系统的人的责任的变化。我们的目标是忠实地反映数据吗?还是我们有义务质疑数据,并设计我们的系统以符合某种公平行为的概念,无论这是否得到我们目前可用数据的支持?这些观点经常处于紧张状态,当我们深入研究机器学习的各个阶段时,它们之间的区别将变得更加清晰。
机器学习循环
让我们研究一下机器学习的管道,了解人口差异是如何通过它传播的。这种方法可以让我们瞥见机器学习的黑匣子,并为我们在后面的章节中进行更详细的分析作准备。如果我们想进行干预以减少差异,研究机器学习的各个阶段是至关重要的。
下图显示了一个使用机器学习产生输出的典型系统的阶段。像任何此类图表一样,它是一种简化,但对我们的目的是有用的。
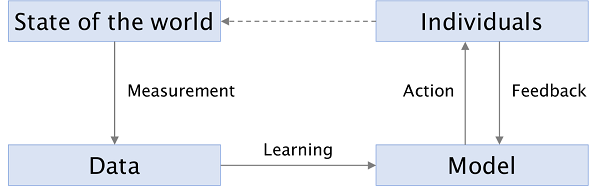 机器学习循环
机器学习循环
第一阶段是测量,这是一个过程,世界的状态被简化为数据集中的一组行、列和值。这是一个混乱的过程,因为现实世界是混乱的。测量这个词有误导性,让人联想到一个冷静的科学家记录她所观察到的东西,而我们将看到它需要人类的主观决定。
机器学习中的 “学习 “指的是下一个阶段,即把这些数据变成一个模型。一个模型总结了训练数据中的模式;它可以进行归纳。一个模型可以通过支持向量机(Support Vector Machines)这样的算法,使用监督学习来训练,或者通过k-means聚类这样的算法,使用无监督学习。它可以采取多种形式:超平面或n维空间中的一组区域,或一组分布。它通常被表示为一组权重或参数。
下一个阶段是我们根据模型的预测而采取的行动,这是模型对新的、未见过的输入的应用。预测 “是另一个具有误导性的术语–虽然它有时确实涉及到试图预测未来(”这个病人是否有患癌症的高风险?”),但通常不是这样。它可以采取分类(确定一封电子邮件是否是垃圾邮件)、回归(给被告分配风险分数)或信息检索(寻找最符合搜索查询的文件)的形式。
这三种应用中的相应动作可能是:将电子邮件存入用户的收件箱或垃圾邮件文件夹,决定是否为被告的审前释放设置保释金,以及向用户显示检索到的搜索结果。它们对个人的意义可能差别很大,但它们的共同点是,个人对这些决定的集体反应改变了世界的状态,也就是系统旨在模拟的基本模式。
一些机器学习系统记录用户的反馈(用户对行动的反应),并利用它们来完善模型。例如,搜索引擎跟踪用户点击的内容,作为相关性或质量的隐含信号。反馈也可以无意中发生,甚至是对抗性的;这些都是比较有问题的,我们将在本章后面探讨。
社会状况
在本书中,我们关注的是涉及*人的数据的机器学习的应用。在这些应用中,可用的训练数据可能会对我们社会中存在的人口差异进行编码。例如,该图显示了美国职业样本的性别分类,基于劳工统计局发布的2017年数据。”美国职业样本中的女性比例。泡沫的面积代表工人的数量。

不出所料,许多职业都有明显的性别不平衡。如果我们要建立一个筛选求职者的机器学习系统,我们应该敏锐地意识到这是我们的起点基线。这并不一定意味着我们系统的输出会不准确或具有歧视性,但在本章中,我们将看到它是如何使事情变得复杂的。
为什么会存在这些差异?有许多潜在的促成因素,包括明确的歧视历史,对性别的隐性态度和定型观念,以及某些特征在性别上的分布差异。我们将看到,即使没有明确的歧视,定型观念也会自我实现,并在社会中长期存在。当我们将机器学习整合到决策中时,我们应该注意确保ML不会成为这种反馈循环的一部分。
那么,那些与人无关的应用呢?考虑一下 “Street Bump”,这是波士顿市的一个项目,旨在众包关于坑洞的数据。智能手机应用程序使用智能手机传感器的数据自动检测坑洞,并将数据发送给城市。基础设施似乎是数据驱动决策的一个令人欣慰的无聊应用,与我们一直在讨论的道德难题相去甚远。
然而! 凯特-克劳福德指出,这些数据反映了智能手机的拥有模式,与低收入地区和老年人口较多的地区相比,城市中较富裕的地区拥有率较高。
这里的教训是,机器学习应用不涉及人的情况很少。在Street Bump的案例中,数据是由人收集的,因此反映了人口差异;此外,我们首先对改善基础设施感兴趣的原因是它对人们生活的影响。
为了说明大多数机器学习应用都涉及人,我们分析了Kaggle,一个著名的数据科学竞赛平台。我们专注于按奖金数额排序的前30项比赛。在其中的14项比赛中,我们观察到任务是对个人进行决策。在大多数情况下,存在着社会上的定型观念或差异,而这些定型观念或差异可能会因为机器学习的应用而延续下去。例如,自动作文评分Kaggle,”休利特基金会。Automated Essay Scoring” ( https://www.kaggle.com/c/asap-aes , 2012)。任务是寻求算法,试图与人类评分员对学生作文的评分一致。学生的语言选择是社会群体成员的标志,众所周知,人类评分员有时会有基于此类因素的偏见。Hanna和Linden,”评分中的歧视”,American Economic Journal: 经济政策》 4, no. 4 (2012): 146-68; Sprietsma, “Discrimination in Grading: 来自小学教师的实验证据,”实用经济学 45,第1期(2013):523-38。因此,由于人类评分员必须提供原始标签,自动评分系统有可能将训练数据中捕捉到的任何此类偏见奉为圭臬。
在30个比赛中的另外5个比赛中,任务并不要求对人做出决定,但使用模型做出的决定还是会直接影响到人。例如,由房地产公司Zillow赞助的一项竞赛要求改进该公司的 “Zestimate “算法,以预测房屋销售价格。任何预测房屋未来售价的系统(并公布这些预测)都可能创造一个自我实现的反馈循环,即预测售价较低的房屋会阻止未来的买家,抑制需求并降低最终售价。
在30个竞赛中的9个竞赛中,我们没有发现对人有明显的直接影响,比如预测海洋健康的竞赛(当然,即使是这样的竞赛也会对人产生间接影响,因为我们可能会根据获得的知识采取行动)。在两个案例中,我们没有足够的信息来做出判断。
总而言之,人类社会充满了人口差异,而训练数据很可能会反映这些差异。我们现在来看看训练数据的构建过程,会发现事情更加棘手。
测量的麻烦
测量这个词暗示了一个简单的过程,让人想到照相机客观地记录了一个场景。事实上,测量充满了主观决定和技术困难。
考虑一个看似简单的任务:测量大学校园的人口多样性。最近《纽约时报》的一篇文章旨在做到这一点,标题是 “即使有平权行动,黑人和西班牙裔在顶尖大学的代表人数比35年前更少。”Ashkenas, Park, and Pearce, “即使有平权行动,黑人和西班牙裔在顶尖大学的代表人数比35年前更少”( https://www.nytimes.com/interactive/2017/08/24/us/affirmative-action.html , 2017)。作者认为,在过去的35年里,入学的黑人和西班牙裔新生与黑人和西班牙裔大学适龄人口之间的差距已经扩大。为了支持他们的说法,他们提出了从1980年到2015年的100多所美国大学和学院的人口信息,并显示了黑人、西班牙裔、亚裔、白人和多种族学生的百分比多年来的变化。有趣的是,多种族类别是最近在2008年才引入的,但文章中的比较忽略了这一新类别的引入。有多少学生可能会选择 “白人 “或 “黑人”,而选择 “多种族”?这可能对这些大学的 “白人 “和 “黑人 “学生的百分比产生了什么影响?此外,个人和社会对种族的概念随着时间而变化。与20世纪80年代相比,父母为黑人和拉丁裔的人在2015年是否更倾向于自我认同为黑人?问题的关键在于,即使是一个关于人口多样性趋势的看似简单的问题,如果不做一些假设,也是不可能回答的,这也说明了在一个不愿意整齐地落入一套复选框的世界里,测量的困难。种族不是一个稳定的类别;我们如何测量种族往往会改变我们对它的概念,而对种族概念的改变可能会迫使我们改变我们的测量。
说白了,这种情况很典型:衡量关于人的几乎任何属性都是类似的主观性和挑战性。如果有的话,当机器学习研究人员不得不创建类别时,事情就会更加混乱,而这也是经常发生的情况。
机器学习从业者经常需要定义新类别的一个领域是在定义目标变量时。Barocas和Selbst,”大数据的差异化影响”,UCLA法律评论,2016。这就是我们要预测的结果–如果被告被保释,他是否会再犯?如果被录用,候选人会是一个好员工吗?等等。
训练集的目标变量中的偏差尤其关键,因为它们保证会使预测出现偏差(其他属性不一定如此)。但是,从测量的角度来看,目标变量可以说是最难的,因为它往往是为了手头的问题而编造的一个结构,而不是一个被广泛理解和测量的结构。例如,”信用度 “是在如何成功地向消费者提供信贷的问题上创造出来的一个结构;Barocas和Selbst.它不是一个人们拥有或缺乏的内在属性。
如果我们的目标变量是 “好员工 “的概念,我们可能会使用绩效评估的分数来量化它。这意味着我们的数据继承了管理者对其报告的评价中存在的任何偏见。另一个例子:使用计算机视觉对人们的身体吸引力进行自动排名。Plaugic,”FaceApp的创造者为该应用程序的皮肤美白 “热 “过滤器道歉”(The Verge。 https://www.theverge.com/2017/4/25/15419522/faceapp-hot-filter-racist-apology ,2017);Manthorpe,”The Beauty.AI Robot Beauty Contest Is Back”(Wired UK。 https://www.wired.co.uk/article/robot-beauty-contest-beauty-ai ,2017)。训练数据包括人类对吸引力的评价,而且毫不奇怪,所有这些分类器都显示出对浅色皮肤的偏好。
在某些情况下,我们也许能够更接近于目标变量的客观定义,至少在原则上是这样。例如,在刑事风险评估中,训练数据不是法官对谁应该获得保释的决定,而是基于谁实际去犯罪。但至少有一个很大的注意事项–我们无法真正衡量谁犯了罪,所以我们用逮捕作为替代。这就用警务工作的偏见取代了法官的偏见。另一方面,如果我们的目标变量是被告是否出庭受审,我们将能够直接准确地测量它。尽管如此,我们仍然可能对一个根据预测的出庭概率而区别对待被告的系统感到担忧,因为有些不出庭的原因比其他原因更令人反感(试图坚守一份不允许休假的工作与试图逃避起诉)。
在招聘中,我们可能不依靠销售工作的绩效评估,而是依靠完成的销售数量。但这是一个客观的衡量标准,还是受制于潜在客户的偏见(他们可能对某些销售人员的反应比其他销售人员更积极)和工作环境(可能对某些人来说是一个敌对的环境,而不是其他)?
在一些应用中,研究人员重新利用现有的分类方案来定义目标变量,而不是从头开始创建一个。例如,可以通过在ImageNet上训练分类器来创建一个物体识别系统,ImageNet是一个以概念的层次结构组织的图像数据库。一个大规模的分层图像数据库”,在Proc. CVPR, 2009。ImageNet的层次结构来自于Wordnet,这是一个关于单词、类别以及它们之间的关系的数据库,Miller, “WordNet: Miller, “WordNet: A Lexical Database for English,” Communications of the ACM 38, no. 11 (1995): 39-41. Wordnet的作者又从一些旧的来源,如辞典中导入了词表。因此,WordNet(和ImageNet)的类别中包含了许多过时的词和关联,比如不再存在的职业和陈旧的性别关联。因此,ImageNet训练的物体识别系统假设的世界分类与它们所处的世界不匹配。
我们认为技术变化迅速,而社会适应缓慢,但至少在这个例子中,作为当今大部分机器学习技术核心的分类方案已经被冻结,而社会规范却变化迅速。
我们最喜欢的测量偏差的例子与照相机有关,我们在本节开头提到了照相机是冷静观察和记录的典范。但它们是吗?
与相机所能捕捉到的东西相比,视觉世界的带宽基本上是无限的,无论是胶片还是数码相机,这意味着摄影技术涉及到一系列关于什么是相关的,什么是不相关的选择,以及基于这些选择对捕捉到的数据进行的转换。胶片和数码相机在历史上都更善于拍摄浅色皮肤的人。Roth,”看着雪莉,最终的规范。色彩平衡、图像技术和认知公平,”加拿大传播杂志34,第1期(2009):111。其中一个原因是默认设置,如色彩平衡,是为浅肤色优化的。另一个更深层次的原因是相机的 “动态范围 “有限,这使得它很难在同一图像中捕捉到更明亮和更暗的色调。这种情况在20世纪70年代开始改变,部分原因是家具公司和巧克力公司分别抱怨难以拍摄到家具和巧克力的细节! 另一个推动力来自于此时电视题材的日益多样化。
当我们从单个图像到图像数据集时,我们又引入了一层潜在的偏见。考虑一下用于训练今天的计算机视觉系统的图像数据集,如物体识别任务。如果这些数据集是底层视觉世界的代表性样本,我们可能会期望在一个这样的数据集上训练的计算机视觉系统在另一个数据集上表现良好。但实际上,当我们在不同的数据集上进行训练和测试时,我们观察到准确率有很大的下降。Torralba和Efros,”无偏见地看待数据集偏见”,在Proc. cvpr(IEE,2011),1521-28。这表明这些数据集在统计意义上相对于其他数据集是有偏见的,是调查这些偏见是否包括文化成见的一个良好起点。
这并不全是坏消息:机器学习事实上可以帮助缓解测量偏差。回到相机的动态范围问题,计算技术,包括机器学习,正在使改善图像中的色调表现成为可能。 Liu, Zhang, and Zhang, “Learning-Based Perceptual Image Quality Improvement for Video Conferencing,” in Multimedia and Expo, 2007 IEEE International Conference on (IEEE, 2007), 1035-38; Kaufman, Lischinski, and Werman, “Content-Aware Automatic Photo Enhancement,” in Computer Graphics Forum, vol. 31, 8 (Wiley Online Library, 2012), 2528-40; Kalantari and Ramamoorthi,” Deep High Dynamic Range Imaging of Dynamic Scenes, ACM Trans. Graph 36, no. 4 (2017): 144. 另一个例子来自医学:诊断和治疗有时是按种族进行个性化的。但事实证明,种族被用作祖先和遗传学的粗略代理,有时是环境和行为因素。Bonham, Callier, and Royal, “Will Precision Medicine Move Us Beyond Race?” 《新英格兰医学杂志》374,第21期(2016年):2003年;威尔逊等人,”可变药物反应的群体遗传结构”,《自然遗传学》29,第3期。3 (2001): 265. 如果我们能够测量这些遗传和生活方式因素,并将它们–而不是种族–纳入疾病和药物反应的统计模型,我们就能提高诊断和治疗的准确性,同时减轻种族偏见。
总而言之,测量包括定义你感兴趣的变量,与现实世界互动的过程,并将你的观察结果转化为数字,然后实际收集数据。通常情况下,机器学习从业者不会去考虑这些步骤,因为别人已经做了这些事情。然而,了解数据的出处是至关重要的。即使别人已经为你收集了数据,对你的算法来说,它几乎总是太乱了,所以才有了可怕的 “数据清洗 “步骤。但是,现实世界的混乱并不只是通过清洗来处理的烦恼,而是数据驱动技术的局限性的表现。
从数据到模型
我们已经看到,训练数据反映了现实世界和测量过程中的差异、扭曲和偏见。这导致了一个明显的问题:当我们从这些数据中学习一个模型时,这些差异是被保留、减轻还是加剧了?
用监督学习方法训练的预测模型通常擅长校准:确保模型的预测包含了数据中的所有特征,以达到预测结果的目的。相比之下,人类的直觉在考虑先验因素方面是出了名的差,这也是统计预测在各种情况下表现更好的一个主要原因。但校准也意味着,在默认情况下,我们应该期望我们的模型能够忠实地反映在输入数据中发现的差异。
下面是另一种思考的方式。训练数据中的一些模式(吸烟与癌症有关)代表了我们希望使用机器学习来挖掘的知识,而其他模式(女孩喜欢粉红色,男孩喜欢蓝色)代表了我们可能希望避免学习的刻板印象。但学习算法没有一般的方法来区分这两类模式,因为它们是社会规范和道德判断的结果。在没有具体干预的情况下,机器学习会提取刻板印象,包括不正确和有害的刻板印象,就像它提取知识一样。
这方面的一个典型例子来自于机器翻译。右边的截图显示了将句子从英语翻译成土耳其语再翻译回来的结果。从英语翻译成土耳其语,然后再翻译成英语,会注入性别定型观念。
![]()
在我们测试过的所有翻译引擎中,许多语言对和其他职业词都会出现同样的定型翻译。这很容易看出原因。土耳其有性别中立的代词,当把这样的代词翻译成英语时,系统会挑选与训练集(通常是一个大型的、经过最小化处理的历史文本和网络上发现的文本语料库)的统计数据最匹配的句子。
当我们从这样的文本中建立一个语言统计模型时,我们应该期望职业词的性别关联能够大致反映现实世界的劳动统计。此外,由于男性作为常态的偏见Danesi, Dictionary of Media and Communications*(Routledge, 2014)。当性别未知时使用男性代词),我们应该期望翻译会偏向男性代词。事实证明,当我们用几十个职业词重复实验时,这两个因素–劳动统计和男性为常态的偏见–共同几乎完美地预测了哪个代词会被返回。Caliskan, Bryson, and Narayanan, “Semantics Derived Automatically from Language Corpora Contain Human-like Biases,” *Science 356, no. 6334 (2017): 183-86.
对于模型反映数据偏见的观察,这里有一个诱人的回应。假设我们正在建立一个模型,为一份编程工作的简历打分。如果我们简单地从数据中扣留性别呢?这样的模型肯定不会有性别偏见?不幸的是,这不是那么简单的,因为存在代理问题Barocas和Selbst,”大数据的不同影响。”或冗余编码,Hardt,”大数据如何不公平”( https://medium.com/@mrtz/how-big-data-is-unfair-9aa544d739de ,2014)。我们将在下章讨论。数据中还有任何数量的其他属性可能与性别相关。在我们的文化中,人们开始编程的年龄与性别相关是众所周知的。这说明了代理变量的另一个问题:它们可能与手头的决定真正相关。一个人编程的时间有多长是一个因素,它给我们提供了关于他们是否适合编程工作的宝贵信息,但它也反映了性别定型观念的现实。
最后,学习步骤也有可能引入训练数据中没有的人口统计差异。这方面最常见的原因是样本大小的差异。如果我们通过从训练数据中均匀取样来构建我们的训练集,那么根据定义,我们会有更少的关于少数民族的数据点。当然,当有更多的数据时,机器学习的效果会更好,所以它对少数群体成员的效果会更差,假设多数群体和少数群体的成员在预测任务方面有系统性的不同.Hardt。
更糟的是,在许多情况下,相对于人口统计,少数群体的代表性不足。例如,少数群体在科技行业的代表性不足。不同的群体也可能以不同的速度采用技术,这可能会歪曲社交媒体上收集的数据集。如果训练集是从这些不具代表性的环境中提取的,那么来自少数民族的训练点就会更少。例如,据报道,许多采用人脸检测技术的产品在处理非高加索人脸时出现了问题,这很容易猜到原因。
当我们开发机器学习模型时,我们通常只测试它们的整体准确性;因此,”5%的错误 “统计可能掩盖了一个事实,即一个模型对一个少数民族群体的表现非常糟糕。按群体报告准确率将有助于提醒我们注意类似上述例子的问题。在下一章,我们将研究量化群体间错误率差异的指标。
在机器学习的一个应用中,我们发现少数民族群体的错误率特别高:异常检测。这是检测偏离常规的行为作为对系统滥用的证据的想法。一个很好的例子是Nymwars的争议,谷歌、Facebook和其他科技公司旨在阻止使用不常见的(因此,可能是假的)名字的用户。
此外,假设在某些文化中,大多数人从一小部分名字中获得名字,而在其他文化中,名字可能更加多样化,而且名字的独特性可能很常见。对于后者文化中的用户来说,一个受欢迎的名字更有可能是假的。换句话说,在一个群体中构成预测证据的同一特征,在另一个群体中可能构成反对预测的证据。
如果我们不小心,学习算法会根据多数文化进行归纳,导致少数群体的错误率很高。这是因为我们希望避免过度拟合,也就是说,挑选出由于随机噪音而不是真实差异而产生的模式。避免这种情况的方法之一是明确建立群体之间的差异模型,尽管这在技术上和道德上都存在挑战,我们将在后面的章节中展示。
行动的隐患
任何真正的机器学习系统都是为了给世界带来一些改变。为了理解它的效果,我们必须在它所处的更大的社会技术系统的背景下考虑它。
在第二章中,我们将看到,如果一个模型是经过校准的–它忠实地捕捉了基础数据中的模式–使用该模型做出的预测将不可避免地对不同的群体产生不同的错误率,如果这些群体有不同的*基础率,也就是积极或消极的结果率。换句话说,理解一个预测的属性不仅需要理解模型,还需要理解预测所适用的群体之间的人口差异。
此外,群体特征会随着时间的推移而改变;这是一个众所周知的机器学习现象,称为漂移。如果子群体随着时间的推移发生不同的变化,就会引入差异。一个额外的问题是:差异是否令人反感,在不同的文化中可能有所不同,并且随着时间的推移,社会规范的演变可能会发生变化。
当人们受制于自动化决策时,他们对这些决策的看法不仅取决于结果,也取决于决策的过程。一个有道德的决策过程可能需要,除其他外,解释预测或决定的能力,这在黑盒模型中可能是不可行的。
机器学习的一个主要限制是,它只揭示了相关性,但我们经常使用它的预测,好像它们揭示了因果关系。这是一个持续存在的问题来源。例如,一个早期的机器学习系统在医疗保健领域学到了一个看似无意义的规则,即哮喘病人患肺炎的风险较低。这是数据中的一个真实模式,但可能的原因是,哮喘病人更有可能接受住院治疗。Predicting Pneumonia Risk and Hospital 30-Day Readmission,” in Proc. 2121St ACM SIGKDD, 2015, 1721-30. 所以用预测结果来决定是否收治病人是不成立的。我们将在第四章讨论因果关系。
另一种看待这个例子的方式是,预测影响了结果(因为在预测的基础上采取了行动),从而使自己无效。同样的原理也见于使用机器学习预测交通拥堵:如果有足够多的人根据预测选择路线,那么被预测为畅通的路线事实上就会拥堵。这种效果也可以在相反的方向上发挥作用:预测可能会加强结果,导致反馈循环。为了更好地理解,让我们来谈谈循环的最后阶段:反馈。
反馈和反馈环路
许多系统在进行预测时都会收到反馈。当搜索引擎提供结果时,它通常会记录用户点击的链接以及用户在这些页面上花费的时间,并将这些作为隐性信号,说明哪些结果被认为是最相关的。当一个视频分享网站推荐一个视频时,它使用大拇指向上/向下的反馈作为一个明确的信号。这种反馈被用来完善模型。
但反馈是很棘手的,要正确解释。如果一个用户点击了搜索结果页面上的第一个链接,这仅仅是因为它是第一个,还是因为它实际上是最相关的?这又是一个行动(搜索结果的排序)影响结果(用户点击的链接)的案例。这是一个活跃的研究领域;有一些技术旨在从这种有偏见的反馈中准确地学习。Joachims, Swaminathan, and Schnabel, “Unbiased Learning-to-Rank with Biased Feedback,” in Proc. 1010Th International Conference on Web Search and Data Mining(ACM, 2017), 781-89.
反馈中的偏见也可能反映出文化偏见,当然这比搜索结果排序的影响更难定性。例如,出现在搜索结果旁边的目标广告的点击率可能反映了性别和种族的定型观念。有一项著名的研究暗示了这一点。谷歌搜索黑人的名字,如 “Latanya Farrell”,比搜索白人的名字(”Kristen Haring”)更有可能出现逮捕记录的广告(”Latanya Farrell,被逮捕?3(2013年3月):10:10-29。一个潜在的解释是,用户更有可能点击符合刻板印象的广告,而广告系统是为了最大化点击率而优化的。
换句话说,即使是设计在系统中的反馈也会导致意想不到的或不理想的偏见。但是,有许多非预期的反馈方式可能会出现,而这些方式更有害,也更难控制。让我们来看看三种情况。
自我实现的预测。假设一个预测性警务系统确定一个城市的某些地区处于犯罪的高风险之中。更多的警察可能被部署到这些地区。或者,在被预测为高风险地区的警察可能会巧妙地降低他们拦截、搜查或逮捕人的门槛–也许甚至是无意识地。无论哪种方式,预测看起来都是有效的,即使它是纯粹基于数据的偏见而做出的。
下面是另一个例子,说明根据预测采取行动可以改变结果。在美国,一些刑事被告在审判前被释放,而对其他被告来说,保释金是作为释放的前提条件。许多被告无法交纳保释金。释放或拘留是否影响案件的结果?也许被拘留的被告面临更大的认罪压力。无论如何,如果不做实验,怎么可能检验拘留的因果影响?耐人寻味的是,我们可以利用一个伪实验,即被告被准随机地分配到保释法官,而一些法官比其他法官更严格。因此,审前拘留是部分随机的,以一种可量化的方式。使用这种技术的研究已经证实,拘留确实会导致定罪的可能性增加。Dobbie, Goldin, and Yang, “The Effects of Pre-Trial Detention on Conviction, Future Crime, and Employment: 来自随机分配的法官的证据”(国家经济研究局,2016)。如果保释金是根据风险预测设定的,无论是人类还是算法,而我们通过检查案件结果来评估其效力,我们会看到一个自我实现的效果。
影响训练集的预测。继续这个例子,预测性警务活动将导致逮捕,其记录可能被添加到算法的训练集。然后,这些地区可能继续出现犯罪的高风险,也许还有其他具有类似人口组成的地区,这取决于用于预测的特征集。这种偏见甚至可能随着时间的推移而加剧。
2016年的一篇论文分析了PredPol的预测性警务算法,这是少数在同行评议期刊上发表的算法之一。PredPol公开发布他们的算法值得称赞,没有它,这项研究甚至不可能实现。通过将其应用于来自奥克兰警方记录的数据,他们发现,黑人将成为毒品犯罪预测性警务的目标,其比率大约是白人的两倍,尽管这两个群体的毒品使用率大致相同。Significance 13, no. 5 (2016): 14-19. 他们的模拟显示,这种最初的偏见会被反馈循环放大,警务工作越来越集中在目标区域。尽管PredPol算法没有明确考虑到人口统计学。
最近的一篇论文建立在这一想法的基础上,从数学上显示了当在预测基础上发现的数据被用来更新模型时,反馈循环是如何发生的。Ensign等人,”Runaway Feedback Loops in Predictive Policing,” arXiv Preprint arXiv:1706.09847, 2017。该论文还展示了如何调整模型以避免反馈循环:通过量化给定预测的犯罪观察有多令人惊讶,并只在应对令人惊讶的事件时更新模型。
影响现象和整个社会的预测。大规模的偏见性警务,无论是否有算法,都会随着时间的推移影响社会,促成贫困和犯罪的循环。这是一个极为成熟的论点,我们将在第三章简要回顾关于持久不平等和陈规定型观念持续存在的社会学文献。
让我们提醒自己,我们部署机器学习是为了能够根据其预测采取行动。甚至很难从概念上消除预测对结果、未来训练集、现象本身或整个社会的影响。机器学习在我们的生活中变得越是核心,这种影响就越强。
回到搜索引擎的例子,在短期内,也许可以从用户的点击中提取一个无偏见的信号,但从长远来看,返回次数多的结果会被链接到,从而排名更靠前。作为实现其检索相关信息的目的的一个副作用,搜索引擎必然会改变其旨在衡量、分类和排名的东西。同样,大多数机器学习系统会影响它们所预测的现象。这就是为什么我们把机器学习过程描绘成一个循环。
在本书中,我们将学习减轻机器学习中的社会偏见的方法,但让我们停下来考虑一下,我们所能实现的目标是有根本限制的,特别是当我们把机器学习视为一个社会技术系统而不是数学抽象时。教科书上的训练和测试数据是独立和相同分布的模型是一种简化,在实践中可能是无法实现的。
用一个玩具的例子来具体说明问题
现在让我们看看一个具体的环境,尽管是一个玩具问题,以说明到目前为止所讨论的许多想法,以及一些新的想法。
假设你是一个招聘委员会的成员,只根据每个申请人的两个属性来做决定:他们的大学GPA和他们的面试分数(我们说过这是一个玩具问题!)。我们将其表述为一个机器学习问题:任务是使用这两个变量来预测申请人的某些 “质量 “指标。例如,它可以基于在该公司工作两年后的平均绩效审查得分。我们将假设我们有来自过去候选人的数据,使我们能够训练一个模型来预测基于GPA和面试分数的绩效分数。

玩具的例子:一个招聘分类器,根据GPA和面试分数来预测工作表现(未显示),然后应用一个截止点。
显然,这是一个归纳性的表述–我们假设一个求职者的价值可以简化为一个数字,并且我们知道如何衡量这个数字。这是一个有效的批评,也适用于今天数据驱动决策的大多数应用。但它有一个很大的优势:一旦我们将决策制定为预测问题,统计方法往往比人类做得更好,即使是经过多年培训的领域专家,也能根据噪声预测器做出决策。这个问题已经得到了很好的研究,我们将在第三章中研究它。
鉴于这样的表述,我们能做的最简单的事情就是使用线性回归来预测两个观察变量的平均工作表现等级,然后根据我们想要雇用的候选人数量来使用一个截止点。上图显示了这可能是什么样子。在现实中,所考虑的变量不需要满足线性关系,因此建议使用非线性模型,为了简单起见,我们避免使用这种模型。
正如你在图中所看到的,我们的候选人分为两个人口统计组,分别用三角形和正方形表示。这种二元分类是为了我们的思想实验而进行的简化。这样的简化在研究文献中也很常见。事实上,大多数提议的公平干预措施本身就是从假设这种分类开始的。但在建立真正的系统时,强制执行僵硬的人的分类可能在伦理上是有问题的。这并不是机器学习所特有的,在许多数据驱动的环境中也出现了类似的矛盾,比如人口普查表或就业申请中的种族复选框。请注意,分类器并没有考虑到候选人属于哪个群体。这是否意味着该分类器是公平的?我们可能希望它是公平的,基于公平即盲目的理念,该理念由戴着眼罩的正义女士的图标所象征。在这种观点中,一个公正的模型–在回归中不使用群体成员身份–是公平的;一个给不同群体的其他相同成员打不同分数的模型是歧视性的。
我们将把对公平的理解推迟到第三章,所以让我们问一个更简单的问题:来自两组的候选人被正面分类的可能性是否相同?答案是否定的:三角形比正方形更有可能被选中。这是因为数据是一面社会的镜子;我们所预测的 “基础事实 “标签–工作表现评级–对于正方形来说系统地低于三角形。
造成这种差异的原因可能有很多。首先,为员工业绩打分的经理可能对某个群体有偏见。或者整个工作场所可能对某一群体有偏见,使他们无法发挥自己的潜力,导致业绩下降。另外,这种差异可能起源于候选人被雇用之前。例如,它可能源于两组人在教育机构中的差异。或者他们之间可能存在内在的差异。当然,它可能是这些因素的组合。我们无法从我们的数据中看出有多少差异是由这些不同因素造成的。一般来说,这样的判断在方法上是很难的,需要进行因果推理。Zhang和Bareinboim,”决策中的公平性–因果解释公式”,见Proc.3232Nd AAAI,2018。
现在,让我们假设我们有证据表明我们的选择程序所产生的人口差异水平是不合理的,而且我们有兴趣进行干预以减少它。我们可以怎么做呢?我们观察到,GPA与人口统计学属性相关–它是一个代理。也许我们可以简单地省略该变量作为预测因素?不幸的是,我们也会削弱我们模型的准确性。在真实的数据集中,大多数属性往往是人口统计学变量的代理变量,放弃它们可能不是一个合理的选择。
另一个粗略的方法是选择不同的截止点,使两组的候选人有相同的被雇用的概率。或者,我们可以通过减少分界线的差异来减轻人口统计学上的差异,而不是消除它。
考虑到现有的数据,没有任何数学上的原则性方法可以知道应该选择哪种分界线。在某些情况下,有一个法律基线:例如,美国平等就业机会委员会的指导方针指出,如果两个群体的选择概率相差超过20%,就可能构成足够的差异性影响,从而提起诉讼。但仅有差异性影响并不违法;差异性需要是不合理的或可避免的,法院才会认定责任。即使是这些量化的准则也没有提供简单的答案或明确的界限。
无论如何,选择不同的门槛来减轻差异的方法似乎不能令人满意。它不再是盲目的,两个具有相同可观察属性的候选人可能会收到不同的决定,这取决于他们属于哪一组。
但还有其他可能的干预措施,我们将讨论一个。为了激发它,让我们退一步问,为什么公司要减少招聘中的人口差异。
一个答案是植根于对个人和他们所属的特定社会群体的公正。但另一个答案来自公司的自私利益:多元化的团队工作得更好。Rock和Grant,”为什么多元化的团队更聪明”(哈佛商业评论。 https://hbr.org/2016/11/why-diverse-teams-are-smarter ,2016)。从这个角度来看,增加被雇用的群体的多样性将有利于公司和群体中的每个人。
我们如何在选择任务中操作多样性?如果我们有一对候选人之间的距离函数,我们可以衡量所选候选人之间的平均距离。作为一个稻草人,我们假设使用基于GPA和面试分数的欧几里得距离。如果我们将这样的多样性标准纳入目标函数,就会产生一个GPA权重较低的模型。这种技术具有盲目性的优势:我们没有明确考虑群体成员,但作为坚持其他可观察属性多样性的副作用,我们也提高了人口多样性。然而,不小心应用这样的干预措施很容易出错:例如,模型可能会给那些与任务完全不相关的属性加权。
更广泛地说,除了为不同群体挑选不同的阈值之外,还有许多可能的算法干预。特别是,个体对之间的相似性函数的想法是一个强大的想法,我们将看到其他利用它的干预措施。但是,在实践中想出一个合适的相似性函数并不容易:可能不清楚哪些属性是相关的,如何对它们进行加权,以及如何处理属性之间的相关性。
其他道德方面的考虑
到目前为止,我们主要关注的是机器学习系统输出中的人口差异所产生的道德问题。但其他几类问题也值得强调。
预测与干预的关系
在不公平的情况下做出的公平的决定可能对改善人们的生活没有什么帮助。在许多情况下,我们不能仅仅通过改变决策来实现任何合理的公平概念;我们需要改变做出这些决定的条件。
让我们回到上面的招聘例子。当使用机器学习来预测某人在特定工作场所或职业中的表现时,我们倾向于将人们在这些角色中所面临的环境视为一个常量,并询问人们的表现将如何根据他们的可观察特征而变化。换句话说,我们把世界的现状当作一个既定事实,让我们去选择在这种情况下表现最好的人。这种方法有可能忽视我们可以对工作场所进行的更根本的改变(文化、家庭友好政策、在职培训),这些改变可能会使工作场所对那些在以前的条件下没有发展起来的人来说更受欢迎,更有成效。Barocas,”将数据用于工作”,在数据和歧视。论文集,编辑。Seeta Peña Gangadharan Virginia Eubanks和Solon Barocas(新美国基金会,2014),59-62。
机器学习中关于公平性的工作的趋势是询问雇主是否使用了公平的选择过程,即使我们可能有机会干预工作场所的动态,这些动态实际上是按照种族、性别、残疾和其他特征来解释预测结果的差异.Jackson和VanderWeele,”分解分析以确定减少差异的干预目标”,流行病学,2018,825-35。
我们可以从所谓的残疾社会模型中学到很多东西,该模型将残疾人在工作中表现出色的预测差异视为缺乏适当的便利条件(无障碍工作场所、必要的设备、灵活的工作安排)的结果,而不是该人本身的任何内在能力。一个人只是在我们没有建立物理环境或采取适当政策以确保他们平等参与的意义上是残疾的。
具有其他特征的人可能也是如此,仅仅改变选拔程序并不能帮助我们解决使某些人无法像其他人那样有效地做出贡献的根本不公正的条件。
准确度
准确性是一个未受重视的伦理问题。它在技术文献中没有得到太多关注的原因是,我们假设决策者有某种效用的概念,而这种效用几乎总是与准确性的最大化直接相关。例如,一家决定谁应该接受贷款的银行可能会使用数据来预测接受者是否会偿还贷款;他们希望尽量减少两种类型的错误–假阳性和假阴性–因为他们会因为假阳性而损失金钱,而因为假阴性而放弃潜在的利润。因此,机器学习问题已经被框定在最大化准确率方面,而且文献中经常谈到准确率-公平的权衡。
然而,有两个原因需要单独考虑准确性作为负责任的机器学习的标准。我们已经讨论过其中一个原因:错误可能在人口统计学群体中分布不均,而效用最大化的决策者可能不会考虑到这一点。
另一个相关的原因是,是否要部署自动决策系统往往是一个需要讨论的问题,而且我们不愿意把这个问题留给市场的逻辑(和奇思妙想)。最近有两场这样的辩论:警察使用面部识别技术是否应该受到监管,以及现在? Garvie, Bedoya, and Frankle, “The Perpetual Lin-up,” Georgetown Law。Center on Privacy and Technology., 2016.这并不是说准确性是决定警方使用面部识别的可接受性的唯一标准。相反,主要关注的是公民自由和警察权力的不负责任。使用DNA测试作为法医工具会出什么问题?了解这些技术的错误率以及错误的性质,对知情的辩论至关重要。
同时,根据这些技术对不同群体的可能准确性来辩论它们的优点,可能会分散对一个更基本问题的注意力:即使这些系统对每个人的表现都一样好,我们是否应该部署这些系统?我们可能要规范警察对此类工具的使用,即使这些工具是完全准确的。我们的公民权利–行动自由和结社自由–在这些技术失败和运作良好时都同样受到威胁。
多样性
多样性是一个有点笼统的术语。它是选择系统中的一个标准,比如上面的招聘例子。我们可能关心多样性的另一种情况是为机器学习构建代表世界的训练数据集。让我们再讨论两个问题。
在信息系统中,低多样性会导致机会的缩小。例如,来自贫困背景的学生不去选择性大学的一个原因是,他们根本不知道有这样的机会。Dillon和Smith,”学生和大学之间不匹配的决定因素”(国家经济研究局,2013年);Jaquette和Salazar,”意见|大学在更富有、更白的高中招聘 - 纽约时报”( https://www.nytimes.com/interactive/2018/04/13/opinion/college-recruitment-rich-white.html ,2018)。在线搜索和广告是缓解这一问题的宝贵途径;然而,这样做需要逆流而上,根据对用户的算法分析来确定广告(有时是搜索)的目标。有证据表明,广告定位有时会以这种方式缩小机会。Datta, Tschantz, and Datta, “Automated Experiments on Ad Privacy Settings,” Proceedings on Privacy Enhancing Technologies 2015, no. 1 (2015): 92-112.
在个性化系统中出现了一个相关的问题:臭名昭著的过滤泡沫。Pariser, The Filter Bubble: What the Internet Is Hiding from You (Penguin UK, 2011)。这是一种观点,即当算法系统学习我们过去的活动来预测我们可能点击的内容时,他们会给我们提供符合我们现有观点的信息。请注意,个人用户可能会喜欢过滤泡沫–事实上,研究表明,与算法推荐相比,我们自己的选择导致了我们在线消费的范围缩小–Bakshy, Messing, and Adamic, “Exposure to Ideologically Diverse News and Opinion on Facebook,” Science 348, no. 6239 (2015): 1130-32.但令人担忧的是,意识形态隔离的民众可能不利于民主的运作。过滤泡沫是搜索引擎、新闻网站和社交媒体的担忧;相关的机器学习技术包括信息检索和协作过滤。
定型观念的延续和文化诋毁
职业术语(如CEO或软件开发人员)的图像搜索结果反映了(可以说是夸大了)这些职业的普遍性别构成和刻板印象。Kay, Matuszek, and Munson, “Unequal Representation and Gender Stereotypes in Image Search Results for Occupations,” in Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems(ACM, 2015), 3819-28. 我们应该关心图像搜索结果中的这种差异吗?毕竟,这些结果并不影响招聘或任何其他重要的决定。而在线翻译中的性别刻板印象又会带来什么危害呢?这些和其他在不同程度上令人不安的例子–例如谷歌的应用程序将美国黑人的照片标记为 “大猩猩”,或自动完成中的攻击性结果–似乎属于不同的道德类别,例如,刑事司法中使用的歧视性系统,它具有直接和具体的后果。
最近的一次谈话阐述了其中的差别。克劳福德,”偏见的麻烦”(NIPS Keynote https://www.youtube.com/watch?v=fMym_BKWQzk , 2017)。当刑事司法、医疗保健等方面的决策系统具有歧视性时,它们会产生分配性伤害,当一个系统扣留某些群体的机会或资源时,就会造成这种伤害。相比之下,其他的例子–陈规陋习的延续和文化诋毁–则是代表性伤害的例子,当系统强化了某些群体在身份–种族、阶级、性别等方面的从属地位时,就会发生这种伤害。
分配性伤害受到了广泛的关注,因为它们的影响是直接的,而且在计算机科学和经济学中它们更容易被正式化和研究。表征性伤害具有长期影响,并且难以被正式描述。但是,随着机器学习成为我们认识世界的一个重要部分–通过搜索、翻译、语音助手和图像标签等技术–表征性伤害将在我们的文化中留下印记,并影响身份的形成和刻板印象的延续。因此,这些是自然语言处理和计算机视觉领域的关键问题。
我们的展望:限制和机遇
我们已经看到机器学习是如何通过测量、学习、行动和反馈等阶段传播世界状态的不平等的。影响人们的机器学习系统最好被认为是闭环,因为我们根据预测采取的行动反过来会影响世界的状态。公平机器学习的一个主要目标是发展对这些差异何时是有害的、不合理的或其他不可接受的理解,并制定干预措施以减轻这种差异。
这一目标存在着基本的挑战和限制。无偏见的测量甚至在原则上也可能是不可行的,正如我们通过例子看到的那样。由于决策者通常不参与测量阶段的工作,因此还有一些实际限制。此外,观察性数据可能不足以确定差异的原因,而这正是设计有意义的干预措施和了解干预效果所需要的。在目前的研究文献中,大多数试图对机器学习进行 “去伪存真 “的尝试都假定了简单的数学系统,往往忽略了算法干预对个人和社会长期状态的影响。
尽管有这些重要的局限性,我们有理由对公平和机器学习持谨慎的乐观态度。首先,与人类决策相比,数据驱动的决策有可能更加透明。它迫使我们阐明我们的决策目标,并使我们能够清楚地了解各种愿望之间的权衡。然而,要实现这种潜在的透明度,还有一些挑战需要克服。一个挑战是提高现代机器学习方法的可解释性和可说明性,这是一个正在大力研究的课题。另一个挑战是数据集和系统的专有性,而这些数据集和系统对于关于这个主题的知情的公共辩论至关重要。许多评论家都呼吁改变现状。Reisman等人,”算法影响评估。公共机构问责的实用框架》( https://ainowinstitute.org/aiareport2018.pdf ,2018)。
其次,许多机器学习应用中确实存在有效的干预措施,特别是在自然语言处理和计算机视觉方面。这些领域的任务(比如说,转录语音)比传统决策(比如说,预测贷款申请人是否会还款)受到的内在不确定性更少,消除了我们将在第二章研究的一些统计限制。
我们乐观的最后一个也是最重要的理由是,转向自动化决策和机器学习提供了一个重新连接公平的道德基础的机会。算法迫使我们明确知道我们想通过决策实现什么。而当我们必须正式说明这些目标时,就更难掩饰我们不明确的或真实的意图。这样一来,机器学习就有可能帮助我们更有效地辩论不同政策和决策程序的公平性。
我们不应该期望机器学习中的公平性工作能够提供简单的答案。我们应该怀疑那些将公平性视为可以简化为算法批准印章的努力。在最好的情况下,这项工作将使我们在辩论和定义公平性时更难避免困难的问题,而不是更容易。它甚至可能迫使我们面对法律和政策中现有的歧视方法的意义和可执行性,Barocas和Selbst,”大数据的差异性影响”,扩大我们所掌握的推理公平和寻求正义的工关于机器学习的介绍,我们请读者参考Hardt和RechtHardt和Recht的文章,Patterns, Predictions, and Actions。A Story about Machine Learning ( https://mlstory.org , 2021), https://arxiv.org/abs/2102.05242 。该书可在mlstory.org网上查阅。WassermanWasserman的一本优秀教科书,《统计学的全部》。A Concise Course in Statistical Inference (Springer, 2010).也提供了额外的统计背景。
本章借鉴了几个关于机器学习和数据驱动决策中的偏见的分类法:Moritz Hardt的博文,Hardt,”How Big Data Is Unfair.” Barocas and Selbst的论文,Barocas and Selbst,”Big Data’s Disparate Impact.” 以及白宫科技政策办公室2016年的一份报告。Munoz, Smith, and Patil,”Big Data: 关于算法系统、机会和公民权利的报告》,总统行政办公室。白宫,2016年。关于人工智能、机器学习和算法系统带来的挑战的广泛调查,见AI Now报告.Campolo等人,”AI Now 2017报告”,纽约大学AI Now研究所,2017年。
一项研究算法系统公平性的早期工作是由Friedman和Nissenbaum在1996年完成的。Friedman和Nissenbaum, “Bias in Computer Systems,” ACM Transactions on Information Systems (TOIS) 14, no. 3 (1996): 330-47. 研究分类中人口差异的论文从2008年开始定期出现;Pedreschi, Ruggieri, and Turini, “Discrimination-Aware Data Mining,” in Proc. 1414Th ACM SIGKDD (ACM, 2008), 560-68. 这一研究的中心在欧洲,在数据挖掘研究界。随着2014年FAT/ML研讨会的成立,一个新的社区出现了,此后这个话题也越来越受欢迎。几本通俗读物对现代社会的算法系统进行了批判。Pasquale, The Black Box Society: 控制金钱和信息的秘密算法(哈佛大学出版社,2015年);奥尼尔,数学毁灭的武器。大数据如何增加不平等和威胁民主(百老汇出版社,2016年);尤班克斯,Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor(圣马丁出版社,2018年);诺贝尔,Algorithms of Oppression: 搜索引擎如何强化种族主义(纽约大学出版社,2018)。具。
我们希望这本书能在刺激这一新生的跨学科研究方面发挥一点作用。
书目说明和进一步阅读
关于机器学习的介绍,我们请读者参考Hardt和RechtHardt和Recht的文章,Patterns, Predictions, and Actions。A Story about Machine Learning ( https://mlstory.org , 2021), https://arxiv.org/abs/2102.05242 。该书可在 mlstory.org 网上查阅。WassermanWasserman的一本优秀教科书,《统计学的全部》。A Concise Course in Statistical Inference (Springer, 2010).也提供了额外的统计背景。
本章借鉴了几个关于机器学习和数据驱动决策中的偏见的分类法:Moritz Hardt的博文,Hardt,”How Big Data Is Unfair.” Barocas and Selbst的论文,Barocas and Selbst,”Big Data’s Disparate Impact.” 以及白宫科技政策办公室2016年的一份报告。Munoz, Smith, and Patil,”Big Data: 关于算法系统、机会和公民权利的报告》,总统行政办公室。白宫,2016年。关于人工智能、机器学习和算法系统带来的挑战的广泛调查,见AI Now报告.Campolo等人,”AI Now 2017报告”,纽约大学AI Now研究所,2017年。
一项研究算法系统公平性的早期工作是由Friedman和Nissenbaum在1996年完成的。Friedman和Nissenbaum, “Bias in Computer Systems,” ACM Transactions on Information Systems (TOIS) 14, no. 3 (1996): 330-47. 研究分类中人口差异的论文从2008年开始定期出现;Pedreschi, Ruggieri, and Turini, “Discrimination-Aware Data Mining,” in Proc. 1414Th ACM SIGKDD (ACM, 2008), 560-68. 这一研究的中心在欧洲,在数据挖掘研究界。随着2014年FAT/ML研讨会的成立,一个新的社区出现了,此后这个话题也越来越受欢迎。几本通俗读物对现代社会的算法系统进行了批判。Pasquale, The Black Box Society: 控制金钱和信息的秘密算法(哈佛大学出版社,2015年);奥尼尔,数学毁灭的武器。大数据如何增加不平等和威胁民主(百老汇出版社,2016年);尤班克斯,Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor(圣马丁出版社,2018年);诺贝尔,Algorithms of Oppression: 搜索引擎如何强化种族主义(纽约大学出版社,2018)。
参考文献
Ashkenas, Jeremy, Haeyoun Park, and Adam Pearce. “Even with Affirmative Action, Blacks and Hispanics Are More Underrepresented at Top Colleges Than 35 Years Ago.” https://www.nytimes.com/interactive/2017/08/24/us/affirmative-action.html, 2017.
Bakshy, Eytan, Solomon Messing, and Lada A Adamic. “Exposure to Ideologically Diverse News and Opinion on Facebook.” Science 348, no. 6239 (2015): 1130–32.
Barocas, Solon. “Putting Data to Work.” In Data and Discrimination: Collected Essays, edited by Seeta Peña Gangadharan Virginia Eubanks and Solon Barocas, 59–62. New America Foundation, 2014.
Barocas, Solon, and Andrew D Selbst. “Big Data’s Disparate Impact.” UCLA Law Review, 2016.
Bonham, Vence L, Shawneequa L Callier, and Charmaine D Royal. “Will Precision Medicine Move Us Beyond Race?” The New England Journal of Medicine 374, no. 21 (2016): 2003.
Caliskan, Aylin, Joanna J Bryson, and Arvind Narayanan. “Semantics Derived Automatically from Language Corpora Contain Human-Like Biases.” Science 356, no. 6334 (2017): 183–86.
Campolo, Alex, Madelyn Sanfilippo, Meredith Whittaker, and Kate Crawford. “AI Now 2017 Report.” AI Now Institute at New York University, 2017.
Caruana, Rich, Yin Lou, Johannes Gehrke, Paul Koch, Marc Sturm, and Noemie Elhadad. “Intelligible Models for Healthcare: Predicting Pneumonia Risk and Hospital 30-Day Readmission.” In Proc. 2121St ACM SIGKDD, 1721–30, 2015.
Crawford, Kate. “The Hidden Biases in Big Data.” Harvard Business Review 1 (2013).
———. “The Trouble with Bias.” NIPS Keynote https://www.youtube.com/watch?v=fMym_BKWQzk, 2017.
Danesi, Marcel. Dictionary of Media and Communications. Routledge, 2014.
Datta, Amit, Michael Carl Tschantz, and Anupam Datta. “Automated Experiments on Ad Privacy Settings.” Proceedings on Privacy Enhancing Technologies 2015, no. 1 (2015): 92–112.
Dawes, Robyn M, David Faust, and Paul E Meehl. “Clinical Versus Actuarial Judgment.” Science 243, no. 4899 (1989): 1668–74.
Deng, J., W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. “ImageNet: A Large-Scale Hierarchical Image Database.” In Proc. CVPR, 2009.
Dillon, Eleanor Wiske, and Jeffrey Andrew Smith. “The Determinants of Mismatch Between Students and Colleges.” National Bureau of Economic Research, 2013.
Dobbie, Will, Jacob Goldin, and Crystal Yang. “The Effects of Pre-Trial Detention on Conviction, Future Crime, and Employment: Evidence from Randomly Assigned Judges.” National Bureau of Economic Research, 2016.
Ensign, Danielle, Sorelle A Friedler, Scott Neville, Carlos Scheidegger, and Suresh Venkatasubramanian. “Runaway Feedback Loops in Predictive Policing.” arXiv Preprint arXiv:1706.09847, 2017.
Eubanks, Virginia. Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor. St. Martin’s Press, 2018.
Friedman, Batya, and Helen Nissenbaum. “Bias in Computer Systems.” ACM Transactions on Information Systems (TOIS) 14, no. 3 (1996): 330–47.
Garvie, Clare, Alvaro Bedoya, and Jonathan Frankle. “The Perpetual Line-up.” Georgetown Law: Center on Privacy and Technology., 2016.
Hanna, Rema N, and Leigh L Linden. “Discrimination in Grading.” American Economic Journal: Economic Policy 4, no. 4 (2012): 146–68.
Hardt, Moritz. “How Big Data Is Unfair.” https://medium.com/@mrtz/how-big-data-is-unfair-9aa544d739de, 2014.
Hardt, Moritz, and Benjamin Recht. Patterns, Predictions, and Actions: A Story about Machine Learning. https://mlstory.org, 2021. https://arxiv.org/abs/2102.05242.
Ingold, David, and Spencer Soper. “Amazon Doesn’t Consider the Race of Its Customers. Should It?” https://www.bloomberg.com/graphics/2016-amazon-same-day/, 2016.
Jackson, John W., and Tyler J. VanderWeele. “Decomposition Analysis to Identify Intervention Targets for Reducing Disparities.” Epidemiology, 2018, 825–35.
Jaquette, Ozan, and Karina Salazar. “Opinion | Colleges Recruit at Richer, Whiter High Schools - the New York Times.” https://www.nytimes.com/interactive/2018/04/13/opinion/college-recruitment-rich-white.html, 2018.
Joachims, Thorsten, Adith Swaminathan, and Tobias Schnabel. “Unbiased Learning-to-Rank with Biased Feedback.” In Proc. 1010Th International Conference on Web Search and Data Mining, 781–89. ACM, 2017.
Kaggle. “The Hewlett Foundation: Automated Essay Scoring.” https://www.kaggle.com/c/asap-aes, 2012.
Kalantari, Nima Khademi, and Ravi Ramamoorthi. “Deep High Dynamic Range Imaging of Dynamic Scenes.” ACM Trans. Graph 36, no. 4 (2017): 144.
Kaufman, Liad, Dani Lischinski, and Michael Werman. “Content-Aware Automatic Photo Enhancement.” In Computer Graphics Forum, 31:2528–40. 8. Wiley Online Library, 2012.
Kay, Matthew, Cynthia Matuszek, and Sean A Munson. “Unequal Representation and Gender Stereotypes in Image Search Results for Occupations.” In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, 3819–28. ACM, 2015.
Liu, Zicheng, Cha Zhang, and Zhengyou Zhang. “Learning-Based Perceptual Image Quality Improvement for Video Conferencing.” In Multimedia and Expo, 2007 IEEE International Conference on, 1035–38. IEEE, 2007.
Lum, Kristian, and William Isaac. “To Predict and Serve?” Significance 13, no. 5 (2016): 14–19.
Manthorpe, Rowland. “The Beauty.AI Robot Beauty Contest Is Back.” Wired UK. https://www.wired.co.uk/article/robot-beauty-contest-beauty-ai, 2017.
Miller, George A. “WordNet: A Lexical Database for English.” Communications of the ACM 38, no. 11 (1995): 39–41.
Munoz, Cecilia, Megan Smith, and D Patil. “Big Data: A Report on Algorithmic Systems, Opportunity, and Civil Rights.” Executive Office of the President. The White House, 2016.
Noble, Safiya Umoja. Algorithms of Oppression: How Search Engines Reinforce Racism. nyu Press, 2018.
O’Neil, Cathy. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. Broadway Books, 2016.
Pariser, Eli. The Filter Bubble: What the Internet Is Hiding from You. Penguin UK, 2011.
Pasquale, Frank. The Black Box Society: The Secret Algorithms That Control Money and Information. Harvard University Press, 2015.
Pedreschi, Dino, Salvatore Ruggieri, and Franco Turini. “Discrimination-Aware Data Mining.” In Proc. 1414Th ACM SIGKDD, 560–68. ACM, 2008.
Plaugic, Lizzie. “FaceApp’s Creator Apologizes for the App’s Skin-Lightening ’Hot’ Filter.” The Verge. https://www.theverge.com/2017/4/25/15419522/faceapp-hot-filter-racist-apology, 2017.
Reisman, Dillon, Jason Schultz, Kate Crawford, and Meredith Whittaker. “Algorithmic Impact Assessments: A Practical Framework for Public Agency Accountability.” https://ainowinstitute.org/aiareport2018.pdf, 2018.
Rock, David, and Heidi Grant. “Why Diverse Teams Are Smarter.” Harvard Business Review. https://hbr.org/2016/11/why-diverse-teams-are-smarter, 2016.
Roth, Lorna. “Looking at Shirley, the Ultimate Norm: Colour Balance, Image Technologies, and Cognitive Equity.” Canadian Journal of Communication 34, no. 1 (2009): 111.
Sprietsma, Maresa. “Discrimination in Grading: Experimental Evidence from Primary School Teachers.” Empirical Economics 45, no. 1 (2013): 523–38.
Sweeney, Latanya. “Discrimination in Online Ad Delivery.” Queue 11, no. 3 (March 2013): 10:10–29.
Torralba, Antonio, and Alexei A Efros. “Unbiased Look at Dataset Bias.” In Proc. CVPR, 1521–28. IEEE, 2011.
Wasserman, Larry. All of Statistics: A Concise Course in Statistical Inference. Springer, 2010.
Wilson, James F, Michael E Weale, Alice C Smith, Fiona Gratrix, Benjamin Fletcher, Mark G Thomas, Neil Bradman, and David B Goldstein. “Population Genetic Structure of Variable Drug Response.” Nature Genetics 29, no. 3 (2001): 265.
Zhang, Junzhe, and Elias Bareinboim. “Fairness in Decision-Making — the Causal Explanation Formula.” In Proc. 3232Nd AAAI, 2018.